3. L - 리스코프 치환 원칙 (Liskov Substitution Principle, LSP)
자식 클래스는 언제나 부모 클래스를 대체할 수 있어야 한다.
부모 클래스의 객체를 사용하는 프로그램에서 자식 클래스로 교체해도 문제가 없어야 함. (업캐스팅을 하여도 문제없어야 함)
잘못된 상속은 이 원칙을 위배함. (자식 클래스에서 부모 클래스의 메서드를 오버라이딩하는 경우)
class Bird {
public void fly() {
System.out.println("Bird is flying");
}
}
class Eagle extends Bird {
public int fly(int a) { // 자기 멋대로 오버로딩을 해버림
System.out.println("it flew " + a + " meters");
}
}
→ 이건 LSP 위반. Eagle이 Bird의 fly를 오버로딩 해버렸기 때문에, 부모 클래스를 자식 클래스로 교체했을 때 원하는 결과가 나오지 않는다.
4. I - 인터페이스 분리 원칙 (Interface Segregation Principle, ISP)
특정 클라이언트를 위한 인터페이스 여러 개가 범용 인터페이스 하나보다 낫다.
사용하지 않는 메서드를 구현하게 만드는 비대한 인터페이스는 나쁘다.
인터페이스는 목적에 맞게 작게 쪼개야 함. (SRP는 클래스를 분리, ISP는 인터페이스를 분리)
한 번 인터페이스를 분리하여 구성해 놓고 나중에 수정사항이 생겨서 또 인터페이스를 분리하는 행위는 지양해야 한다.
interface Printer { // 프린터의 인터페이스
void print();
}
interface Scanner { // 스캐너의 인터페이스
void scan();
}
// 사용자는 필요한 인터페이스만 구현
class SimplePrinter implements Printer {
public void print() {
System.out.println("Printing...");
}
}
5. D - 의존 역전 원칙 (Dependency Inversion Principle, DIP)
고수준 모듈은 저수준 모듈에 의존해서는 안 된다. 둘 다 추상화에 의존해야 한다.
구현 클래스가 아니라 인터페이스나 추상 클래스에 의존하게 만들어야 함.
의존 관계를 맺을 때 변화하기 쉬운 것 또는 자주 변화하는 것보다는 , 변화하기 어려운 것이나 거의 변화하가 없는 것에 의존하라는 뜻
인터페이스나 추상 클래스는 일종의 설계도이기 때문에 변화가 없음. 만약 어떤 클래스를 참조해야 하는 상황이 생긴다면, 그 클래스를 직접 참조하는 것이 아니라 그 대상의 상위 요소(설계도)를 참조하라는 뜻.
interface MessageSender {
void send(String message);
}
class EmailSender implements MessageSender {
public void send(String message) {
System.out.println("Sending Email: " + message);
}
}
class NotificationService {
private MessageSender sender;
// 생성자 주입
public NotificationService(MessageSender sender) {
this.sender = sender;
}
public void notify(String message) {
sender.send(message);
}
}
자바의 OOP(Object-Oriented Programming, 객체지향 프로그래밍)는 객체(Object)를 중심으로 프로그램을 설계하고 구성하는 패러다임이다. 자바는 객체지향 언어로 설계되었기 때문에 OOP의 4대 핵심 개념을 중심으로 구조화된다.
객체란?
여기서 객체란 현실 세계의 사물이나 개념을 프로그램 안에서 표현한 실체를 의미한다.
즉, 어떤 "것"을 코드로 표현했을 때, 그 "것"이 바로 객체이다.
객체는 속성(필드)과 동작(메서드)을 함께 가지고 있는 독립된 단위이다.
객체의 예시를 하나 들어보겠다.
강아지를 객체로 표현한다면 다음과 같다.
속성(필드): 이름, 나이, 품종, 색깔 등 → 데이터
동작(메서드): 짖는다, 뛴다, 먹는다 등 → 기능
public class Dog {
// 속성(필드, 데이터)
String name; // 개 이름
int age; // 개 나이
// 동작(메서드)
void bark() {
System.out.println("멍멍!");
}
}
이렇게 클래스를 정의하고 실제로 사용할 때 객체를 생성해서 쓰면 된다.
Dog myDog = new Dog(); // Dog 클래스를 이용해 "객체" 생성
myDog.name = "콩이";
myDog.age = 2;
myDog.bark(); // 출력: 멍멍!
4대 핵심 개념
다시 OOP로 돌아와서 4대 핵심 개념에 대해 적어보겠다.
OOP의 4대 핵심 개념은 다음과 같다:
캡슐화(Encapsulation)
상속(Inheritance)
다형성(Polymorphism)
추상화(Abstraction)
예시 코드와 함께 각 개념의 정의와 목적을 알아보겠다.
1. 캡슐화 (Encapsulation)
정의: 객체의 속성과 메서드를 하나로 묶고, 외부에서 직접 접근하지 못하도록 보호하는 것
목적: 데이터 보호, 유지보수 용이성
예시:
public class User {
private String name; // 외부에서 직접 접근 불가
public String getName() { // 외부에서 호출 가능
return name; // getter
}
public void setName(String name) { // 외부에서 호출 가능
this.name = name; // setter
}
}
캡슐화는 관련이 있는 변수와 함수를 하나의 클래스로 묶고, 외부에서 쉽게 접근하지 못하도록 은닉하는 게 핵심이다. 이것을 정보은닉(Information Hiding)이라 한다.
정보은닉의 장점은 다음과 같다.
유지보수나 확장 시 오류의 범위를 최소화 할 수 있다.
객체의 정보손상 및 오용을 방지한다.
조작법이 바뀌어도 사용법 자체는 바뀌지 않는다 (함수 호출)
데이터가 바뀌어도 다른 객체에 영향을 주지 않기 때문에 독립성이 보장된다.
모듈화가 가능하다.
위에 예시로 든 User 클래스의 경우 데이터(String name)은 직접 접근이 불가능하고, 해당 데이터를 변경하기 위해서는 함수(getName(), setName())으로만 가능하다.
2. 상속 (Inheritance)
정의: 기존 클래스(부모)의 속성과 기능을 새로운 클래스(자식)가 물려받는 것
목적: 코드 재사용성 증가, 계층적 구조화
예시:
public class Animal { // 부모 클래스
String name;
public void eat() {
System.out.println("먹는다");
}
}
public class Dog extends Animal { // 부모 Animal을 상속 받은 자식 클래스
public void bark() {
System.out.println("짖는다");
}
}
상속 개념은 쉽게 말해 부모 클래스(상위 클래스)와 자식 클래스(하위 클래스)가 있으며, 자식 클래스는 부모 클래스의 대부분의 것을 상속 받아 그대로 쓸 수 있다는 것을 의미한다. (private 접근 제한을 갖는 데이터 및 함수는 상속받지 못한다.)
상속을 하는 이유는 간단하다. 이미 만들어진 클래스를 재사용하여 코드의 재사용성을 늘리고, 개발 시간을 단축시키기 위해서다.
위에 예시로 든 Dog는 Animal의 name과 bark()를 상속 받아서 사용 가능하다.
Dog doggy = new Dog();
dog.name = "White"; // Dog 내부에는 없지만 Animal의 name을 상속 받아서 사용 가능
dog.bark();
dog.eat(); // 위와 마찬가지
3. 다형성 (Polymorphism)
정의: 같은 타입의 참조 변수가 다양한 객체를 참조할 수 있도록 함
종류:
오버로딩(Overloading): 같은 메서드 이름을 다른 파라미터(매개변수)를 주어 중복 정의
오버라이딩(Overriding): 부모 메서드를 자식이 재정의
예시:
class Animal {
public void sound() {
System.out.println("소리");
}
}
class Cat extends Animal { // Animal을 상속 받음
// 오버라이딩
@Override
public void sound() { // Animal의 sound()를 Cat의 sound()로 재정의
System.out.println("야옹");
}
// 오버로딩
public void eat() {
System.out.println("냠냠");
}
public void eat(String eatSound) { // eat()와 같은 이름이지만 다른 매개변수를 가졌음
System.out.println(eatSound);
}
}
Animal a = new Cat();
a.sound(); // "야옹"
String catFood = "챱챱"
a.eat(); // "냠냠"
a.eat(catFood); // "챱챱"
다형성이란 하나의 객체나 메소드가 여러 가지 다른 형태를 가질 수 있는 것을 말한다.
서로 상속 관계에 있는 부모 클래스와 자식 클래스 사이에서만 사용된다.
업캐스팅과 다운캐스팅도 알아두면 좋다.
4. 추상화 (Abstraction)
정의: 복잡한 내부 구현은 숨기고, 필요한 부분만 노출하는 것
방법:
추상 클래스: abstract class와 abstract method
인터페이스: 다중 구현 지원
예시:
// abstract class 추상화 클래스
// 일반 메서드 또는 멤버 변수를 가질 수 있다.
abstract class Machine {
public String country; // 멤버 변수
public void stop() { // 일반 메서드
System.out.println("정지");
}
// abstract method 추상화 메서드
abstract void operate(); // Machine을 상속 받는 하위 클래스는 operate를 구현해야한다.
}
class Printer extends Machine {
void operate() { // operate를 구현한다.
System.out.println("인쇄 중...");
}
}
// interface 인터페이스
// 상수와 추상메서드만 가질 수 있다.
// (java 8 버전부터는 default와 static 메서드가 추가되어 사용 가능하다.)
public interface Animal {
public static final String name = "이름";
final int weight = 10;
static int age = 1;
abstract void sound(); // Animal을 상속 받는 하위 클래스는 sound를 구현해야한다.
}
public interface Feline {
abstract void move(); // Feline을 상속 받는 하위 클래스는 move를 구현해야한다.
}
// 다중 상속 가능
class Cat implements Animal,Feline {
void sound() { // sound를 구현한다.
System.out.println("야옹");
}
void move() { // move를 구현한다.
System.out.println("사뿐사뿐");
}
}
추상화는 상위 클래스에서클래스들의 공통적인 속성과 동작을 정의하고 이를 하위 클래스에서 구현하는 것이다.
간단하게 말하자면 개집 구조의 설계도만 작성하고 이를 만들어서 꾸미는 것은 제작자한테 맡기는 것이다.
추상화는 abstract 제어자를 가지는 abstract class와 abstract method
오늘은 도커를 활용하여 Spring 프로젝트를 로컬에서 띄우는 방법과 DB와 연결하는 방법에 대해서 써보겠다.
주의 및 정보 :
내 PC에 Docker Desktop이 설치되어 있어야 함.
IDE로 Intellij를 사용하고 있으나 Eclipse에서도 동일하게 동작함.
.jar로 아티팩트를 빌드하지 않고 .war로 아티팩트를 만들어서 실행할 것임.
jar는 Spring Boot 프로젝트에서 사용하는 형태이다. jar로 빌드하고 싶다면 Spring에서 Spring Boot 프로젝트로 기반을 바꿔야 함.
Maven을 사용하여 빌드할 것이다.
DB는 MySQL을 사용하고 있다.
1. 도커 이미지 생성 준비
도커로 Spring프로젝트를 띄우고 싶다면 우선 도커 이미지를 먼저 만들어야 한다.
도커 이미지란 파일로 애플리케이션 실행에 필요한 독립적인 환경을 포함하며, 런타임 환경을 위한 일종의 템플릿이다.
도커 이미지에는 소스 코드, 라이브러리, 종속성, 도구 및 응용 프로그램을 실행하는데 필요한 기타 파일을 포함하는 파일이다.
이미지가 없다면 컨테이너를 실행할 수 없다.
1-1. Dockerfile 만들기
도커이미지 생성을 위해 프로젝트 디렉터리에 Dockerfile을 만들어주겠다.
'프로젝트 디렉터리(여기서는 board) 우클릭 > 새로 만들기 > 파일'을 눌러 빈 파일을 만들어주고
그 파일의 이름을 Dockerfile로 변경해 준다.
Dockerfile에는 이미지 생성에 필요한 명령어들이 들어간다.
# 1. Java 11 + Tomcat 9 베이스 이미지 사용
FROM tomcat:9.0-jdk11-temurin
# 2. 기존 webapps 제거
RUN rm -rf /usr/local/tomcat/webapps/*
# 3. WAR 복사
COPY *.war /usr/local/tomcat/webapps/ROOT.war
# 4. 포트 노출
EXPOSE 8080
# 5. 톰캣 실행
CMD ["catalina.sh", "run"]
FROM : 도커의 베이스이미지를 지정한다. war 파일의 경우 jar와 다르게 자체적으로 실행할 수 없으므로 톰캣 같은 웹 서버 컨테이너에 배포해서 실행해야 하므로 tomcat을 베이스 이미지로 지정해 주겠다.
RUN : tomcat을 설치해서 실행해 보면 알다시피 tomcat 기본 웹서비스라던지 샘플 파일들이 들어가 있다. 그 파일들을 제거해 주는 명령어를 작성한다.
COPY : 나중에 Maven으로 빌드할 아티팩트를 베이스이미지로 지정한 톰캣에 복사해 주는 명령어다.
EXPOSE : EXPOSE 지시어는 컨테이너가 실행될 때 컨테이너로 들어오는 트래픽을 특정 포트로 받아들일 수 있도록 지정하는 역할이다.
CMD : 컨테이너가 실행될 때 실행할 커맨드를 입력한다. 톰캣을 띄우기 위한 명령어를 입력한다.
도커 이미지 생성을 위한 Dockerfile의 작성이 끝났다.
이어서 이미지에 들어갈 아티팩트를 빌드해 주겠다.
1-2. 내 프로젝트 빌드
프로젝트 빌드를 위해 인텔리제이에서 설정을 하겠다.
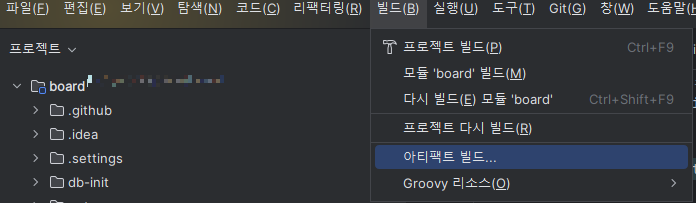
1. '파일 > 프로젝트 구조'를 클릭하여 프로젝트 구조창을 열고
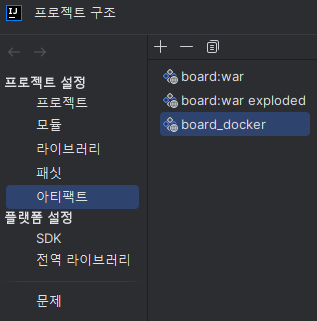
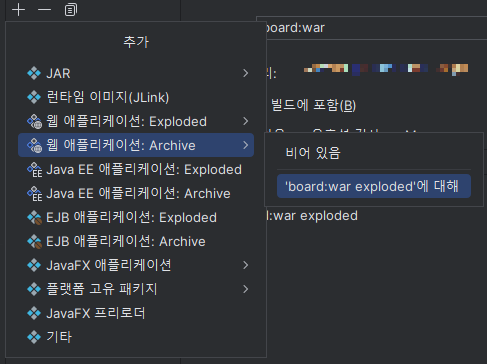
2. '프로젝트 설정 > 아티팩트 > '+' 버튼 > 웹 애플리케이션 Archive > '내 프로젝트명:war exploded'에 대해 클릭 '을 클릭하여 새로운 빌드 생성 준비
3. 빌드 이름은 개인이 원하는 방식으로 작성하고
출력 디렉터리는 Dockerfile이 위치한 경로로 지정한다.
확인을 눌러 변경 사항을 저장하고 이어서 빌드를 하겠다.
인텔리제이에서 '빌드 > 아티팩트 빌드 > 방금 위에서 만든 빌드 선택' 빌드를 진행한다.
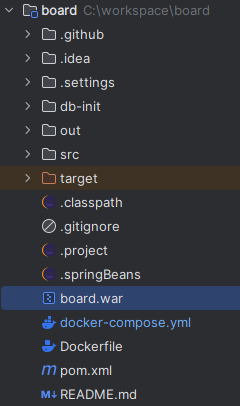
빌드가 완료되면 내가 지정한 출력 디렉터리에서 war 파일을 확인이 가능하다.
빌드와 Docker파일이 생성되었으므로 이제 컨테이너를 띄워보겠다.
명령콘솔을 열어 Dockerfile이 위치한 경로로 이동해서 아래의 명령어를 순서대로 입력하면 이미지가 생성되고 컨테이너가 띄워질 것이다.
my-project-name과 my-container-name은 본인이 원하는 이름을 적어 넣으면 된다.
성공적으로 띄워졌는지는 http://localhost:8080으로 접속해서 확인 가능하다.
이렇게 해서 이미지를 컨테이너에 성공적으로 띄웠다면 이제는 DB와 연결을 해보도록 하겠다.
2. DB와 내 프로젝트 연결 준비
내 프로젝트와 연결된 로컬 DB가 있고 로컬에서 DB가 실행 중일 때 컨테이너를 띄웠다면, DB와 내 Spring앱이 연결이 안 되는 걸 확인할 수 있다.
이런 현상이 발생하는 이유는 도커 컨테이너는 완전히 독립된 네트워크 공간에서 동작하기 때문에 locahost:3306에 띄워진 로컬 DB랑 연결을 못하는 것이다.
이것을 해결하기 위해서는 Docker Compose로 DB도 컨테이너로 띄워야 한다.
도커 컴포즈(Docker Compose)란 단일 서버에서 여러 개의 컨테이너를 하나의 서비스로 정의해 컨테이너들을 묶음을 관리할 수 있는 작업 환경을 제공하는 관리도구이다.
우리는 웹서버와 DB를 각각 다른 컨테이너로 띄우고 동시에 운영을 할 것이다.
DB를 도커 컨테이너로 띄우기 위해서는 로컬 DB에서 스키마 구조와 초기 데이터를 담은 DDL과 DML 쿼리를 가져와야 한다.
2-1. DB 데이터 Export (덤프 준비)
나는 DDL과 초기데이터 둘 다 필요하기 때문에 아래의 방법으로 쿼리를 준비했다.
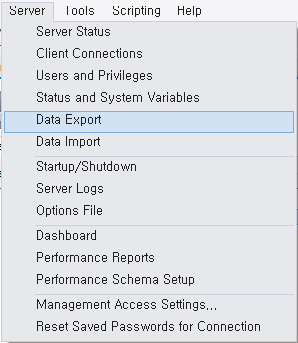
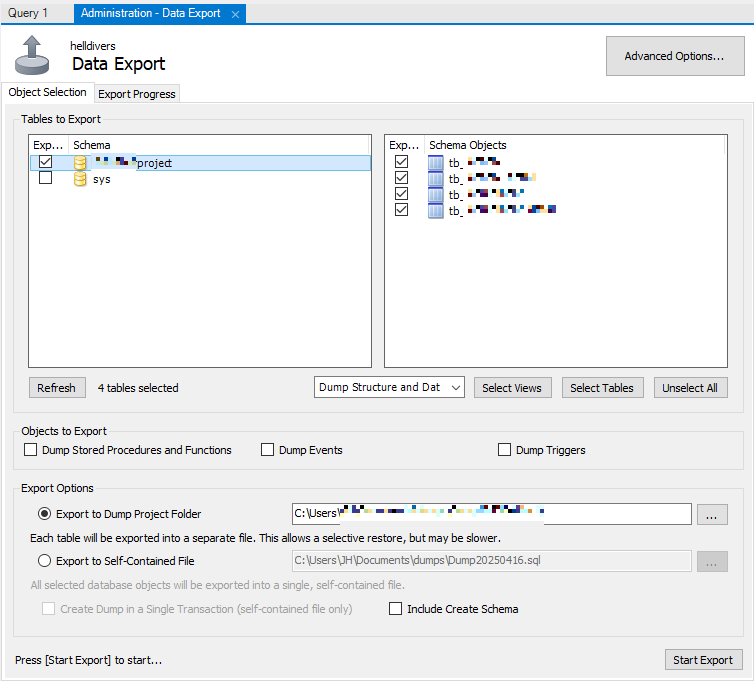
1. MySQL workbench를 실행하여 'Server > Data Export' 선택
2. 테이블 구조와 초기데이터를 가져올 스키마 선택 후
Dump 디렉터리 설정하고 Start Export 버튼을 눌러 추출
3. Dump 디렉터리로 가보면 sql 파일들을 확인 가능하다.
2-2. Docker Compose 준비
sql 파일이 준비가 되었다면 Dockerfile일 위치한 경로에 db-init 폴더를 만들어주고 sql 파일들을 복사 붙여 넣기 해준다.
my-project/
├── Dockerfile // 이미지 생성을 위한 도커파일
├── my-project.war // 아까 빌드한 내 프로젝트
├──
└── db-init/ // 덤프한 sql 파일을 넣어둘 db-init 경로 생성
└── init1.sql
└── init2.sql // sql 파일들 위치
...
만약 컨테이너에서 테이블 생성 시 Foreign Key(외래키)등 제한 조건들로 인해 테이블 생성 순서가 중요하다면 각 sql 파일 이름 앞에 아래와 같이 숫자를 입력해 줘서 생성 순서를 지정해줘야 한다.
db-init/ // 덤프한 sql 파일을 넣어둘 db-init 경로 생성
└── 01_init1.sql // 01 부터 02,03...n번 순으로 실행된다.
└── 02_init2.sql
...
이제 Docker Compose를 생성을 위한 docker-compose.yml을 Dockerfile이 위치한 경로에 만들어 주겠다.
docker-compose.yml은 아래와 같이 작성하면 된다. 주석이 붙어있는 부분들을 내 프로젝트 정보에 맞춰 작성하면 된다.
version: "3.8"
services:
db:
image: mysql:8 // mysql DB 버전
container_name: my-db // db를 띄울 컨테이너 이름
environment:
MYSQL_ROOT_PASSWORD: root
MYSQL_DATABASE: myproject // root-context.xml에 작성되어 있는 스키마명
MYSQL_USER: root //내 DB 계정명
MYSQL_PASSWORD: 1q2w3e4r //내 DB 계정 비밀번호
ports:
- "3306:3306" // localhost:3306과 컨테이너 내부의 3306 포트 연결
volumes:
- dbdata:/var/lib/mysql
- ./db-init:/docker-entrypoint-initdb.d
web:
build: .
container_name: my-container-name // 아까 컨테이너로 실행한 내 프로젝트 컨테이너 명
ports:
- "80:8080" // http://localhost:8080 이 보기 싫으면 80포트 입력
depends_on:
- db // 위에 작성한 db와 내 웹서버를 연결
volumes:
dbdata:
2-4. root-context.xml 수정
docker-compse.yml을 작성 완료했다면 마지막으로 수정이 필요한 파일이 있다.
Spring 애플리케이션 전체에서 공유되는 공통 리소스 정보를 하나 수정해줘야 한다.
해당 정보는 root-context.xml에 저장되어 있다.
root-context.xml에서 DB와 연결되는 정보가 있는데 여기서 url 정보를 수정해 줘야 한다.
myproject?를 db?로 바꿔주기만 하면 된다.
<!-- 기존 로컬 DB 연결 -->
<!--<property name="url" value="jdbc:log4jdbc:mysql://localhost:3306/myproject?useUnicode=true&characterEncoding=utf8"></property>-->
<!-- 도커용 -->
<property name="url" value="jdbc:log4jdbc:mysql://db:3306/myproject?useUnicode=true&characterEncoding=utf8" />
root-context.xml의 정보를 수정하고 저장했다면
위에서 했던 거처럼 프로젝트를 다시 한번 빌드해서 war 파일을 만들어준다.
3. Docker Compose를 실행하여 웹서버와 DB 동시 실행
war파일을 새로 빌드했다면 이제 모든 준비가 끝났으므로 웹서버와 DB 컨테이너를 동시에 실행해 보겠다.
아래의 명령어를 순서대로 실행하면 된다.
만약 DB를 만든 적이 있다면 0. 번 명령어를 실행해서 DB를 제거해 주고 그게 아니라면 1번부터 순차적으로 실행하면 된다.
# 0. 이전에 만든 DB가 있다면 해당 DB 볼륨 초기화
# docker-compose down -v # 이전 db 제거
# 1. 새로 시작하는 것이라면
docker-compose down
# 2. 컨테이너 + DB + 웹 한 번에 빌드 및 실행
docker-compose up --build
Docker 컨테이너가 성공적으로 띄워졌다면
http://localhost:8080로 접속해서 서비스를 확인해 보자.
여기까지가 로컬 환경에서 Spring 기반 애플리케이션과 DB를 띄우고 연결하는 방법에 대해 작성해 보았다.
만약 AWS에서 컨테이너로 띄운다고 하면
1. 웹서버의 이미지를 도커 허브로 올리고
2. EC2에서 해당 이미지를 pull 해서 도커 컴포즈를 실행하면 되고
RDS로 DBMS를 따로 운영한다고 하면
0. RDS에 내 데이터베이스 생성
1. root-context.xml의 url 정보를 AWS RDS url 정보로 변경
db? -> 내 RDS명. ap-northeast-2.rds.amazonaws.com? 으로 변경
이번 글에서는 개인 프로젝트 진행하면서 CI 구축을 해보고 그 방법과 경험을 작성하려고 한다.
우선 AWS 서버가 준비가 된 게 없어서 CD는 나중에 구축할 예정이다.
GitHub Actions란?
GitHub Actions는 github에서 제공하는 서비스로 빌드, 테스트, 배포까지 CI/CD 자동화를 편리하게 해 준다.
GitHub Actions로 CI 구축하기
우선 내 프로젝트가 이미 깃헙 레포지토리에 올라가 있다는 가정하에 작성하겠다.
1. 워크플로우(workflow) 작성
워크플로우란 레포지토리에 사용자가 지정한 이벤트(푸시, 풀, 등...)가 레포지토리에서 발생할 시 트리거되어 동작하는 자동화 프로세스이다.
워크플로우는 깃헙에서 제공하는 템플릿이 많으니 굳이 머리 아프게 경로,파일 생성하고 할 필요가 없다.
레포지토리에서 상단 메뉴를 보면 'Actions'라는 메뉴가 보일 거다.
Actions 탭을 눌러보면 여러 가지 템플릿을 보여주는데. 레포지토리에 올라온 프로젝트의 소스를 보고 추천 템플릿을 제공한다.
나는 프로젝트를 Maven을 이용하여 빌드했기 때문에 'Java with Maven'을 선택해 주었다.
추천 탬플릿들내가 선택한 템플릿
# This workflow will build a Java project with Maven, and cache/restore any dependencies to improve the workflow execution time
# For more information see: https://docs.github.com/en/actions/automating-builds-and-tests/building-and-testing-java-with-maven
# This workflow uses actions that are not certified by GitHub.
# They are provided by a third-party and are governed by
# separate terms of service, privacy policy, and support
# documentation.
name: Java CI with Maven
on:
push:
branches: [ "main" ]
pull_request:
branches: [ "main" ]
jobs:
build:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v4
- name: Set up JDK 17
uses: actions/setup-java@v4
with:
java-version: '17'
distribution: 'temurin'
cache: maven
- name: Build with Maven
run: mvn -B package --file pom.xml
# Optional: Uploads the full dependency graph to GitHub to improve the quality of Dependabot alerts this repository can receive
- name: Update dependency graph
uses: advanced-security/maven-dependency-submission-action@571e99aab1055c2e71a1e2309b9691de18d6b7d6
기본으로 생성된 템플릿(maven.yml)은 이렇다.
위에서부터 하나하나 설명을 하겠다.
1. 이벤트 트리거 설정
on은 무슨 이벤트가 발생했을 때 워크플로우가 트리거 되어 동작할 건지 지정하는 것이다.
나는 master 브랜치에 내 프로젝트를 올려놨으니 master 브랜치에 push나 pull 이벤트가 발생할 경우 동작할 거라 명시했다.
2차원 평면 위의 점 N개가 주어진다. 좌표를 y좌표가 증가하는 순으로, y좌표가 같으면 x좌표가 증가하는 순서로 정렬한 다음 출력하는 프로그램을 작성하시오.
입력
첫째 줄에 점의 개수 N (1 ≤ N ≤ 100,000)이 주어진다. 둘째 줄부터 N개의 줄에는 i번점의 위치 xi와 yi가 주어진다. (-100,000 ≤ xi, yi ≤ 100,000) 좌표는 항상 정수이고, 위치가 같은 두 점은 없다.
출력
첫째 줄부터 N개의 줄에 점을 정렬한 결과를 출력한다.
예제 1
5
0 4
1 2
1 -1
2 2
3 3
예제 2
1 -1
1 2
2 2
3 3
0 4
간단한 문제이다.
Arrays.sort()와 Comparator를 이용하면 금방 풀 수 있다.
이차원 배열 arr[N][2]이 있다. (N은 주어진 좌표 개수, 2는 x,y 좌표를 의미)
배열 arr을 Arrays.sort()를 이용하여 정렬할 때, 우리만의 정렬 기준(Comparator)을 선언해 준다.
우선 arr[N][2]를 열어보면
아래와 같이 배열 안에 작은 배열이 있는 식으로 볼 수 있다.
arr = { {1, 2} ,
{2, -1},
{-1, 2},
.... }
Comparator에 우리가 선언할 compare은 arr 안의 작은 배열의 값을 비교하여 정렬하는 것이다.
// 핵심
Arrays.sort(arr, new Comparator<int[]>() {
@Override
public int compare(int[] a, int[] b){
if(a[1] == b[1]){ // arr[i][1] == arr[i+1][1] 두 점의 Y 좌표를 비교
return a[0]-b[0]; //같으면 X의 값을 비교하여 정렬
} else {
return a[1]-b[1]; //다르면 Y의 값을 비교하여 정렬
}
}
});
전체 코드는 다음과 같다.
import java.io.BufferedReader;
import java.io.InputStreamReader;
import java.util.Comparator;
import java.util.Arrays;
public class BOJ11651_AlignTwoCoordinate {
public static void main(String[] args) throws Exception{
BufferedReader br = new BufferedReader(new InputStreamReader(System.in));
int n = Integer.parseInt(br.readLine());
int[][]arr = new int[n][2];
// 좌표를 배열에 담기
for(int i=0;i<n;i++){
String[] a = br.readLine().split(" ");
arr[i][0] = Integer.parseInt(a[0]);
arr[i][1] = Integer.parseInt(a[1]);
}
// 핵심
Arrays.sort(arr, new Comparator<int[]>() {
@Override
public int compare(int[] a, int[] b){
if(a[1] == b[1]){
return a[0]-b[0];
} else {
return a[1]-b[1];
}
}
});
for(int i=0; i<n; i++){
System.out.println(arr[i][0] + " " + arr[i][1]);
}
}
}
최근 AWS에 대해서 공부 중이며 내가 공부한 여러가지 디자인 패턴에 대해서 작성할려고 한다.
이번 글에서는 다소 복잡한 웹사이트의 예로 AWS를 사용한 기업 웹사이트 구축 패턴에 대해 공부한걸 작성해 보겠다.
기업 웹사이트 개요 :
공개 웹사이트로 사용자는 거래처, 잠재거 고객, 입사지원자 등이다.
정적 콘텐츠 중심이다. (CSS, HTML, 이미지 파일 등)
서버를 다중화하여 장애에 대비한다.
부하가 높아지면 서버를 추가할 수 있게 구성한다.
장애 서버의 교체, 추가는 수동으로 조작한다.
응답시간과 비용을 고려하여 구성한다.
인프라 핵심 :
웹 서버 다중화 : 이벤트 사이트를 구동시킬 최적의 리전을 선택한다.
DB 서버 다중화 : 소규모 웹서버에 맞는 EC2 인스턴스를 설정한다.
CDN과 객체 저장소를 사용한 정적 콘텐츠 전송 : 웹 서버로의 접속을 줄여 운용 비용을 절감한다.
CDN(Content Delivery Network, 콘텐츠 전송 네트워크)은 지리적인 제약 없이 전 세계 사용자에게 빠르고 안전하게 컨텐츠를 전송할 수 있는 기술을 의미한다. 단순하게 얘기하자면 이미지 파일같은 용량이 큰 컨텐츠는 요청이 들어올때마다 서버에서 다운로드 받는것보다. 사용자의 위치에서 가까운 서버에서 캐싱된 컨텐츠를 가져와 빠르고 저렴하게 서비스를 제공해주는 것이다. AWS에서는 Cloudfront 서비스를 통해 제공 받을 수 있다.
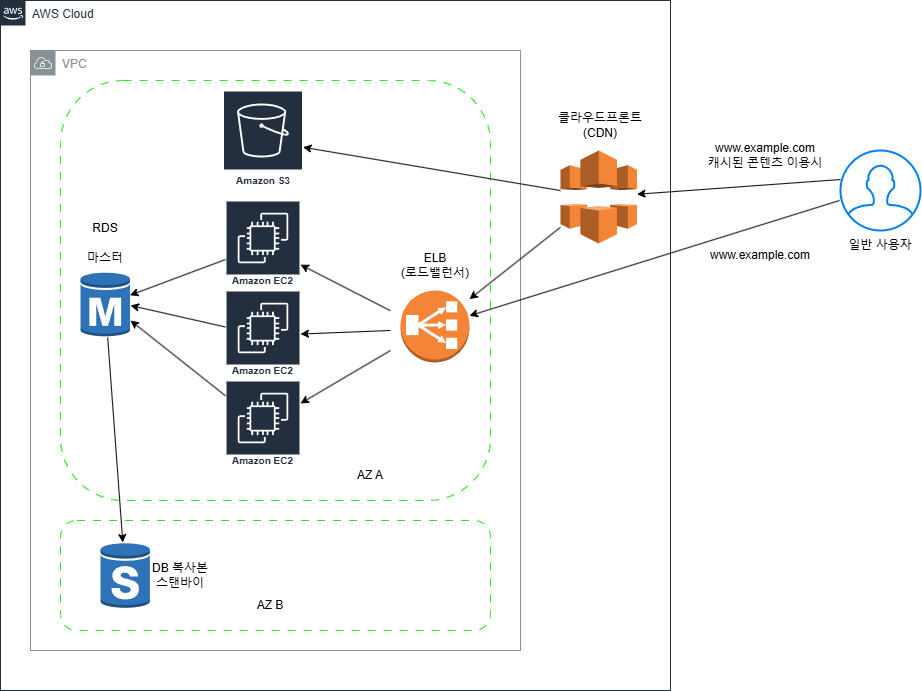
기업 웹사이트 구성도
이전 패턴(이벤트 사이트)과 똑같이 서버를 구성하는 가장 기본적인 서비스는 가상 서버인 EC2(Amazon Elastic Computer Cloud)와 가상 스토리지 볼륨인 EBS(Amazon Elastic Block Store)로 구성한다.
웹서버는 로드 밸런서를 사용하여 다중으로 구성한다. 로드밸런서 기능을 제공하는 AWS 서비스는 ELB(Elastic Load Balancing)이다.
DB 서버는 RDB의 관리형 서비스인 RDS(Amazon Relational Database Service)로 구성한다. RDS는 이미 세팅이 완료된 RDBMS환경을 제공하는 서비스이며 설정만으로도 다중화가 가능핟.
정적 컨텐츠 전송에 이용하는 CDN 서비스는 위에서 잠깐 얘기한 클라우드프론트(Clouldfront)이고, 객체 저장소 서비스는 S3(Amazon Simple Storage Service)이다. CDN을 사용하면 전세계에 배치된 서버를 통해 웹 접속을 캐시하거나 분배할 수 있고, 또한 응답 속도를 높이거나 웹서버로의 접속을 줄여주어 비용 절감에 도움이 된다. S3 저장소는 객체 단위로 데이터를 다루는 스토리지로서 REST API를 사용하여 데이터의 입출력을 수행한다.
ELB를 이용하여 웹 서버 다중화
다중화를 위해서는 웹 서버를 여러 대를 구축해야한다.
이벤트 사이트에서 EC2 인스턴스를 구성하는 방법과 동일한 방법으로 인스턴스를 작성하고, 웹 서버 환경 구축하고, OS 환경을 셋업하고, 필요한 SW를 설치하는 것을 여러번 반복해도 되지만 이것은 시간이 오래 걸린다.
이를 해결하기 위해 있는것이 AMI(Amazon Machine Images)이다. 완성된 인스턴스의 이미지를 저장하는 방식으로 AMI를 만들고, 이 AMI를 이용하여 동일한 구성의 EC2 인스턴스를 여러개 만들 수 있다.
필요한 수의 웹 서버를 만든 후에는 ELB와 연계한 다중화 구성을 한다. ELB를 웹 트래픽의 입구로 사용하여 트래픽이 복수의 웹 서버에 분산되어 부하를 줄이도록 구성한다.
ELB에 의한 부하 분산 설정(EC2 - ELB - 인터넷 연결 설정)은 다음과 같이 설정한다 :
우선 인터넷 접속 엔드포인트를 ELB로 지정한다. ELB는 IP 주소가 아닌 CNAME(대체 도메인명)을 지정하여 접속.
ELB의 IP 주소는 고정이 아니라 계속 변하기 때문이다. DNS 서버인 Route53을 이용하여 ELB의 CNAME과 사용할 도메인 이름을 연결한다. 이러한 설정에 의해 사용자는 도메인 이름을 통해 ELB에 접속할 수 있게 된다.
다음은 ELB와 웹 서버의 EC2 인스턴스를 연결시킨다. ELB 작성 페이지에 웹 서버를 선택하는 항목을 찾아서 이미 만들어진 웹 서버를 선택한다. 이것으로 ELB를 활용한 부하 분산 설정이 끝이다.
- ELB 설정 시 유의 사항
ELB 설정할 때 주의해야 할 다섯 가지
1. ELB용과 웹 서버용으로 각각 다른 보안 그룹을 마련한다.
- ELB는 인터넷 어디에서라도 HTTP/HTTPS 접속을 허용하도록 설정되어 있다. 반면에 웹서버는 ELB로 부터 HTTP 요청만을 받아들이도록 트래픽 소스를 ELB가 속한 보안그룹으로 한정되어야 한다.
EC2 인스턴스 보안 그룹 인바운드 설정
타입
프로토콜
포트 범위
소스
HTTP
TCP
80
10.0.0.24/24 (ELB 보안 그룹)
ELB 보안 그룹 인바운드 설정
타입
프로토콜
포트범위
소스
HTTP
TCP
80
0.0.0.0/0
HTTPS
TCP
443
0.0.0.0/0
ELB 리스너 설정
로드밸런서 프로토콜
로드밸런서 포트
인스턴스 프로토콜
인스턴스 포트
HTTP
80
HTTP
80
HTTPS
443
HTTP
80
2. 세션 유지 기능의 유무 확인
- 최근 웹사이트는 세션 유지 기능을 이용해 복잡한 기능을 지닌 애플리케이션을 제공하는 경우가 있다. 그때 세션 정보를 웹 서버 간에 공유하는 구조를 마련하지 않으면 동일한 클라이언트 접속을 항상 같은 웹 서버에 유지시켜야만 한다. ELB는 ELB 자신이 작성하는 쿠키 저보를 바탕으로 동일한 서버로 접속을 유지시키는 세션 유지 기능을 제공한다. AWS 콘솔에서 설정할 수 있으므로 필요에 따라 사용해야한다.
3. HTTPS 처리
- HTTPS 통신은 클라이언트와 서버 간의 통신을 암호화 한다. ELB는 SSL 터미네이션이라고 하는 SSL 인증서 확인 및 암복호화 처리 기능을 제공한다. ELB 리스너 설정에서 로드밸런스 프로토콜을 HTTPS로 인스턴스의 프로토콜을 HTTP로 하면 자동적으로 적용된다. 웹 서버별로 SSL 인증서를 관리할 필요가 없어질 뿐만 아니라, SSL 복호화 처리에 걸리는 부하가 줄어들어 EC2 비용을 줄일 수 있다.
4. 헬스 체크
- 웹 서버가 정상적으로 동작하는지 감시하는 기능을 헬스 체크라 한다. 기본 설정에서는 간격이 30초, 타임 아웃이 5초, 비정상 상한치가 2회이다. 웹 서버에 장애가 발생하면 40초에서 70초 만에 감지하여 해당 서버를 분리한다. 너무 짧게 설정하면 웹 서버의 부하가 높아져 응담이 저하되는 상태를 고장으로 오판하여 서버가 분리되어 버린다. 반대로 너무 길면 오류가 발생하는 웹 서버에 요청 배분을 계속하게 된다. 기본 설정으로도 충분하지만 성능 시험이나 운영 시 검출 오작동이 발생한다면 수치를 조정하면 된다.
5. 타임아웃 설정
- 응답시간에 따른 타임아웃 설정을 한다. 웹 서버에 분산시킨 후 일정시간 응답이 없으면 ELB는 웹 서버와의 접속을 절단하고, 클라이언트에 HTTP 504를 반환한다. 타임 아웃 시간은 접속 설정의 타임아웃으로 설정하며, 초기 설정 값은 60초이다. DB 처리 등으로 시간이 오래 걸리더라도 결과를 반환하고 싶다면 시간을 길게 설정한다.
RDS를 이용하여 DB 서버 다중화
AWS에서 RDB를 구성하는 방법은 크게 두 가지이다.
EC2인스턴스에 RDBMS를 설치하는 방법과, 관리형 서비스인 아마존 RDS를 이용하는 방법이다.
전자는 OS와 RDBMS를 자유롭게 선택하고 설정할 수 있는 반면, OS와 DB환경을 사용자가 직접 관리하지 않으면 안 된다. 후자는 패치 적용과 백업이 자동화되어 있기 때문에 운영의 번거로움이 줄어든다.
이용 목적에 맞는 방법을 선택하면 된다.
이번에는 RDS 이용을 전제로 한다. AWS에서 제공하는 RDS 엔징으로는 오라클, SQL Server, MySQL, PostgreSQL, Aurora등 다양한 엔진이 존재한다. 어떤 RDS를 사용해도 문제는 없지만, 예시로 MySQL를 사용한다. MySQL은 웹 애플리케이션과 함꼐 사용되는 경우가 많아 찾아 볼 수 있는 기술 정보가 많다.
DB 서버의 다중화는 'Active-Standby(활성-대기' 구성을 선택했다. DB 서버는 데이터의 일관성을 유지하고자 실행 서버를 시스템 안에서 하나로 구성하는 것이 일반적이다. RDS의 멀티-AZ 기능을 사용하면 활성 DB 서버(마스터)의 데이터를 대기 서버(스탠바이)에 동기화하는 복제 중복 구성을 쉽게 구축할 수 있다.
멀티-AZ 기능을 사용한 RDS 설정 방법은 다음과 같다.
매니지먼트 콘솔의 RDS 설정 화면에서 DB 서브넷 그룹을 작성한다. DB 서브넷은 두 가용 영역(AZ)에 각각 서브넷을 만들고 이것을 그룹화해서 만든다 (위의 그림처럼) . 두 AZ를 사용해 서브넷을 만드는 이유는 하나의 AZ가 예상치 못한 재해로 멈추더라도 또 다른 AZ에 설치된 서브넷에 서버가 계속 동작하도록 하기 위함이다.
다음은 RDS for MySQL의 인스턴스를 작성한다. 이때 멀티-AZ를 이용하는 옵션을 선택하고 방금 만든 DB 서브넷 그룹을 지정한다.
이것으로 마스터와 스탠바이 2대 구성의 DB 서버(RDS 인스턴스)가 만들어 졌다. 마스터유저가 자동으로 생성되므로 이를 통해서 애플리케이션 사용자를 만들거나 객체, 그리고 데이터를 관리할 수 있다. 마스터와 스탠바이가 복제되어 있기 때문에 마스터에 장애가 발생해도 데이터는 손실되지 않으나, 2대의 RDS 인스턴스가 동시에 작동하기 때문에 2배의 비용이 발생한다.
마스터 DB 서버에 장애가 발생하면 스탠바이가 마스터로 승격되고 기존 마스터 서버가 사용하던 서브넷에 스탠바이 서버가 새롭게 만들어진다. 이러한 일련의 작업은 자동으로 이루어지기 때문에 별도의 작업은 필요 없으나, DB 접속은 장애 복구 이후 자동으로 연결되도록 사전에 설정해주어야 한다.
- RDS 사용 시 유의 사항
RDS 사용시 유의사항에 대해 적어본다.
첫 번째로 적절한 스냅샷을 생성해야 한다. RDS는 자동 백업과 수동 스냅샷 백업 방법을 지원한다. 자동 백업은 간편하지만 데이터 보존 기간에 제한이 있다. 기본 설정값은 1일, 최대로 35일이다. 시스템에 대한 백업을 영구적으로 저정하려면 스냅샷이 더 적합하다.
두 번째는 AWS에 의한 정기정검이다. RDS는 몇 달에 한 번꼴로 마이너 버전업이 자동으로 실행되어, 약 30분간 정지된다. 옵션으로 마이너 버전 자동 업그레이드를 비활성화하면 마이너 버전업은 수행이 되지 않는다. 하지만 취약점 대응 등에 위한 강제 업그레이드가 이루어지는 경우도 있으니 주의하자.
마지막으로 멀티-AZ를 이용하면 데이터 갱신 처리에 드는 시간이 길어진다. 마스터에 업데이트한 데이터를 스탠바이에 동기화시키는 처리가 끝날 때까지 마스터는 다음의 처리를 실시할 수 없다. 이용 환경이나 처리내용에 따라 다르지만 대체로 20~50% 정도 업데이트 처리 시간이 길어진다.
정적 콘텐츠를 낮은 비용으로 배포하기
방문자가 많은 시스템에서는 이미지와 동영상, 자바스크립트, HTML, CSS 등의 정적 콘텐츠 제공에 많은 비용이 들게 된다. 대량의 트래픽을 처리하려면 고성능 웹 서버가 여러 대 필요하게 되는데, 이렇게 되면 EC2에서 다운로드 통신량이 늘어나서 비용이 증가된다. 이때 정적 콘텐츠 전달 비용을 줄이려면 클라우드프론트와 S3를 사용하면 된다.
클라우드프론트는 위에서 말한거처럼 AWS에서 제공하는 CDN이다. 사용자가 요청한 콘텐츠가 캐싱되어 있으면 웹 서버와 DB 서버에 접속하지 않으므로 서버의 부하를 낮춰 비용을 절감할 수 있다.
클라우드프론트뿐만 아니라 정적 콘텐츠를 S3에 두는 방법을 함께 사용하면 더욱 웹 서버의 부하를 줄일 수 있다. S3에 파일을 저정하면 파일 단위로 접속용 URL이 생성된다. 이것을 이용해 정적 콘텐츠 저장소로 사용한다. S3 요금 체계는 EC2 보다 낮게 설정되어 있기 때문에 정적 콘텐츠를 S3에 배치하는 것이 좋다.
요구사항 2에 대응하려면 장기 이용을 약정하여 할인받을 수 있는 EC2 인스턴스가 적합하다.
성능의 안정성과 관련해서는 스토리지 I/O 대역폭에 주의해야한다. EC2 인스턴스와 EBS 볼륨 사이는 다른 사용자와 공유하는 네트워크로 연결되어 있다. 트래픽이 대역폭의 한계치에 이르게 되면 스토리지에서 데이터를 읽는 데 시간이 걸리고 응답도 불안정해진다. 다양한 네트워크 대역폭이 있지만, 운용 초기에는 성능이 낮은 인스턴스를 설정하고, 부족하면 서능이 높은 인스턴스 타입으로 변경하여 이용하면 좋다.
또한 안정을 중시하는 경우에는 다음의 두 가지 옵션의 사용을 고려해보면 좋다. 첫 번째는 EC2 인스턴스의 옵션인 'EBS 최적 인스턴스'이다. 이 옵션을 사용하면 EC2 인스턴스에서 EBs 볼륨까지 네트워크 대역폭을 보장받을 수 있다. 인스턴스 타입에 따라 이 옵션의 지원 여부가 달라진다.
EBS 최적 인스턴스
또 한 가지 옵션은 '프로비저닝된 IOPS'이다. 프로비저닝된 IOPS를 사용하는 경우, 안정적으로 1만 IOPS이상의 I/O를 보장 받을 수 있다.
성능을 안전시키려면 EBS 최적화를 이용하면 되고, 피크 시 성능을 높이려면 EBS 최적화와 프로비저닝된 IOPS를 모두 사용하면 된다.
요구사항 2에 대응하려면 장기 이용에 따른 할인 혜택을 받기 위해 예약 인스턴스(RI) 사용을 검토하면 된다. EC2 인스턴스 과금 체계 중에서 사용한 만큼 비용을 지불하는 온디맨드 인스턴스가 기본적으로 선택이 된다. 예약 인스턴스는 1년 또는 3년의 기간을 정하여 사용을 예약하면 된다.