


최근 AWS에 대해서 공부 중이며 내가 공부한 여러가지 디자인 패턴에 대해서 작성할려고 한다.
이번 글에서는 사용자 수가 많지 않고 짧은 기간만 서비스하는 이벤트 사이트 패턴에 대해서 써 보겠다.
이벤트 사이트는 일반 소비자를 대상으로 일시적으로 운용할 소규모 웹 서버를 설계하는 걸 목표로 한다.
이벤트 사이트(소규모 웹 서버) 개요 :
- 1개월 한정으로 이용한다.
- 사이트의 사용자는 개인 사용자로서 인터넷으로 접속한다.
- 접속자 수는 많지 않아 고사양 서버는 필요 없다.
- 웹 서버로 LAMP(Linux, Apache, PHP, MySQL) 환경을 사용한다. (다른 환경도 가능하다.)
- 비용을 우선하며 다중화나 백업은 고려하지 않는다. (일회성)
인프라 핵심 :
- 리전 선택 : 이벤트 사이트를 구동시킬 최적의 리전을 선택한다.
- EC2 인스턴스 설정 : 소규모 웹서버에 맞는 EC2 인스턴스를 설정한다.
- 도메인을 통한 접속 : 고정 IP 주소로 접속한다. (CNAME을 설정해 도메인 이름으로도 가능하게 한다.)
- 네트워크 구성 : 인터넷 접속을 위한 간단한 네트워크 구성을 설정한다.
- OS 환경 설정 : 아마존 리눅스에서 LAMP 환경을 설정한다.
이벤트 사이트 구성도

서버를 구성하는 가장 기본적인 서비스는 가상 서버인 EC2(Amazon Elastic Computer Cloud)와 가상 스토리지 볼륨인 EBS(Amazon Elastic Block Store)로 구성한다.
네트워크에 필요한 서비스는 VPC(Virtual Private Cloud)와 같은 기본 서비스에 포함되어 있다. 예시로 VPC의 내부에 가상 라우터를 설치할 수 있고, Route53(Amazon Route 53)을 사용하면 도메인(호스트명)으로 DNS 기능도 제공할 수 있다.
리전 선택 및 네트워크 구성
- 리전에 따른 응답 속도와 비용차이
서비스 구축 시 가장 먼저 해야 하는 것은 바로 서버가 위치할 리전을 선택하는 것이다.
응답 속도는 AWS 데이터 센터와 일반 사용자가 지리적으로 가까울수록 빠르며 멀수록 느려진다.
국내에 거주하는 사용자를 대상으로 하는 이벤트 사이트의 경우 응답 속도를 빠르게 하고 싶다면 서울 리전을 선택하면 된다.
비용은 리전에 따라 다르게 책정된다. 예시로 EC2 타입 중 하나인 t2.micro의 경우
서울 리전의 온디맨드 비용이 시간당 0.0162 달러, 미국 서부 리전은 0.0156 달러로 차이가 나며 데이터 전송 요금도 차이가 난다.
응답 속도보다 비용이 중요하다면 더욱 싼 리전을 찾아보면 된다.


서비스를 시작하고 나면 리전 변경에 손이 많이 가기 때문에 신중해야한다.
- 네트워크 구성
리전을 정했으면 VPC와 서브넷을 구성하는 가상 네트워크를 작성한다.
VPC는 논리적으로 격리된 사용자 전용 네트워크 구역을 의미한다. 복수의 가용 영역(AZ, Availability Zones)에 걸친 형태로 VPC 하나를 작성할 수 있다.
하지만 복수의 리전에 걸쳐서 작성할 수 없으니 주의한다.
서브넷은 VPC를 논리적으로 분리한 서브네트워크로 AWS 환경 내의 네트워크 최소 단위이다.
서브넷은 단일 AZ 안에서만 작성된다.

서브넷을 나누는 방법은 온프레미스 환경과 다른게 거의 없다. 논리적인 네트워크를 설게해서 AWS의 서브넷 구성에 대입시키면 된다. 예를 들어 인터넷으로 HTTP 수신이 가능한 웹 서버와, 웹 서버로부터 데이터베이스 접속만 허가하는 데이터베이스 서버는 필터링 정책이 다르기 때문에 서브넷을 분리해야 한다.
EC2 인스턴스 작성하기
VPC와 서브넷 설정을 완료하고 나서 이벤트 사이트의 웹 서버가 되는 EC2 인스턴스를 작성해야한다.
LAMP로 구성하기로 했으니 EC2 이미지중 Amazon Linux AMI를 사용한다. 가상화 타입으로는 완전가상화인 HVM과 반가상화인 PV가 있는데, 보통은 HVM을 선택한다. (HVM 성능이 더 좋다)
인스턴스 유형은 서버 규모에 해당하며, CPU, 메모리, 스토리지, 네트워크 성능의 조합을 할 수 있다.
하지만 메모리만 늘린다든지 세세한 사용자 정의는 할 수 없다.
그러므로 목적에 가장 가까운 인스턴스 유형을 선택해야 하는데, 작은 LAMP 환경이라면 OS에 약 1GB, MySQL 등의 미들웨어에 1GB정도만 있으면 된다.

네트워크 및 셧다운 동작 설정 주의 사항
인스턴스 유형을 정했다면 다음은 EC2 인스턴스 설정을 해야한다.
주요 포인트만 몇가지 적겠다.
네트워크는 VPC를 선택한다. (기본으로 설정된다)
퍼블릭 IP 주소를 자동할당은 비활성화 해준다. 활성화하면 동적 퍼블릭 IP 주소가 부여되면 EC2 인스턴스가 다시 시작할 때마다 자동으로 변경됨으로 IP주소나 DNS를 다시 지정해주어야만 한다.

EC2 인스턴스를 정지하는 경우의 종료동작 설정도 해줘야한다. 셧다운 동작에는 중지(Stop)와 종료(Terminate)가 있다.
중지를 선택하면, 셧다운 시에 OS가 정지되며 OS 이미지가 보존되고 재시작하면 같은 상태로 시작한다.
종료를 선택하면 OS 정지와 동시에 EC2 인스턴스가 삭제된다. 고급설정에 종료동작을 설정할 수 있으니 확인해 준다.
보안그룹 설정
EC2 설정의 마지막 단계는 보안 그룹 설정이다.
보안 그룹은 OS레벨에서 네트워크 통신 필터링 룰을 정하는 것으로 허가할 프로토콜을 설정한다.
보안그룹 Source의 초기 설정 값이 Anywhere(0.0.0.0/0) 되어 있는데. 이는 모든 IP 주소로부터의 SSH 접속을 허가한다는 의미이다. SSH의 Source값을 집 또는 회사의 퍼블릭 IP 로 설정한다.
이벤트 사이트의 웹 서버는 사용자로부터 HTTP/HTTPS 접속을 허가할 필요가 있다.
이때는 어떤 IP에서든 접속 할 수 있게 0.0.0.0/0으로 설정한다.
| Type | Protocol | Port Range | Source |
| SSH | TCP | 22 | 집 또는 회사의 퍼블릭 IP |
| HTTP | TCP | 80 | 0.0.0.0/0 |
| HTTPS | TCP | 443 | 0.0.0.0/0 |

고정 IP와 호스트명 설정
EC2 인스턴스를 생성했지만, 아직은 인터넷으로 EC2에 접속할 수 없다.
인터넷으로 접속하려면 고정된 퍼블릭 IP주소와 FQDN(호스트명)이 있어야 한다.
고정 퍼블릭 IP 주소를 AWS에서는 EIP(Elastic IP)라고 부른다.
EIP를 포함한 서비스 설정 변경과 추가는 매니지먼트 콘솔에서 한다. EIP 설정은 콘솔을 통해 EC2 서비스로 들어가 '네트워크 및 보안 > 탄력적 IP > 탄력적 IP 주소 할당' 을 클릭하여 설정한다.
자세한건 아래의 블로그를 참조하면 되겠다.
https://any-ting.tistory.com/71
[AWS] 고정 아이피(Elastic IP) 생성 및 설정
- 개요 안녕하세요. 이번 시간에는 AWS Elastic IP(탄력적 아이피)에 대해 알아보겠습니다. 탄력적 아이피는 EC2 인스턴스에 고정 아이피를 설정할 때 사용됩니다. EC2 인스턴스를 상태가 중지 상태에
any-ting.tistory.com
고정 IP를 할당 받았다면 도메인을 설정할 차례이다.
AWS는 Route53이라는 DNS 서비스를 제공한다.
도메인 취득 방법은 아래의 블로그를 참조하면 된다.
https://any-ting.tistory.com/84
[AWS] Route53 도메인 구매(등록)
- 개요 안녕하세요. 이번 시간에는 AWS 도메인을 구매하는 방법에 대해 알아보겠습니다. 기본적으로 AWS 계정이 필요합니다. (이 글을 보시는 분들은 있으시겠죠? :>) 도메인 DNS에 대해서는 따로 설
any-ting.tistory.com
이후 Route53과 EC2 연결은 아래의 블로그 글을 참고하면 된다.
https://dogfoottech.tistory.com/257
[AWS] 도메인과 서버(EC2) 연결하기
서비스를 배포하기 위해서는 도메인이 필수입니다 도메인을 통해 IP로는 나타낼 수 없는 자신의 서비스에 대한 아이덴티티를 도메인을 통해 나타내는 것은 물론 사용자들도 편하게 서비스에 접
dogfoottech.tistory.com
VPC 설정으로 인터넷 접속 설정
인터넷에 접속하려면 한가지 더 설정을 해야한다. AWS에서는 VPC 이용이 필수이다.
VPC는 AWS 데이터 센터 내부에 마련된 가상의 폐쇄 네트워크이며 외부와 통신할 수 있도록 설정해야 한다.
이벤트 사이트는 기본 설정에서 두 군데만 수정하면 된다.
첫 번째는 VPC와 DNS 관련 설정이다. VPC 설정 화면에서 DNS 관련 설정을 켜준다.
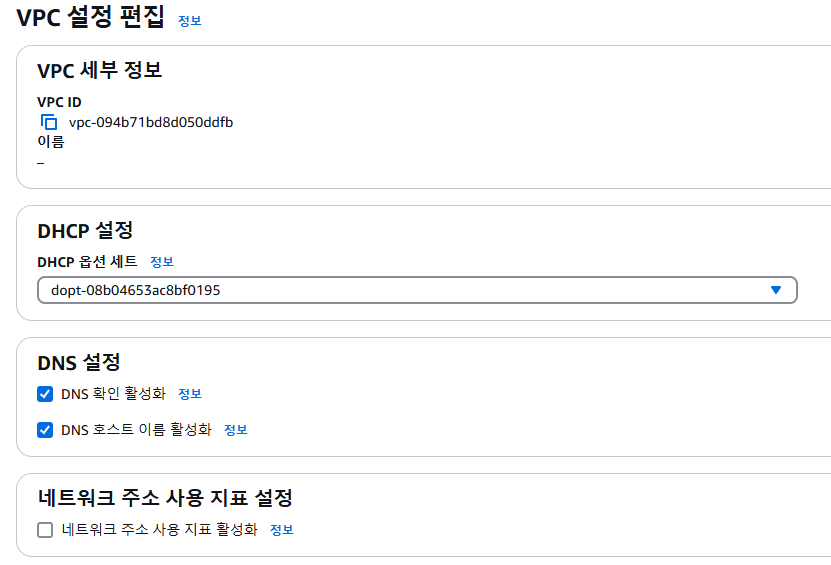
두 번쨰는 라우팅 설정이다. 라우팅 테이블에 인터넷 게이트웨이가 설정되어 있지 않으면 인터넷 접속이 불가능하다. VPC 설정화면에서 라우팅 테이블에서 0.0.0.0/0과 igw로 시작하는 인터넷 게이트가 없다면 생성해준다.
이 블로그 글을 보면 도움이 될 것이다.
AWS 클라우드 구축 (2) - VPC 구축(서브넷, 라우팅 테이블, 인터넷 게이트웨이)
2021. 07. 25 Post PROJECT 가상의 고객사 시스템 구축과 운영 SI AWS 클라우드 환경 구성 쿠버네티스 기반 EKS 환경 구성, 웹서비스 구축 SM 로그 수집을 위한 EFK Stack 구축 CloudWatch 알람을 Slack
velog.io
OS 환경 설정
이 블로그 글을 참고하면 될거 같다.
https://strong-ming.tistory.com/3
AWS 패턴 구축(1.LAMP 환경 구축/리소스 유연하게 변경하기)
AWS-SAP 공부와 실습을 같이 하면 좋을 것 같아서 '배워서 바로 쓰는 14가지 AWS 구축 패턴' 책을 통해 14가지 패턴을 구축하고자 한다. 패턴1_웹 시스템_이벤트 사이트 1.개요 - 1개월 한정 - 사이트 사
strong-ming.tistory.com
마지막으로 이벤트 사이트의 사용기간이 끝났으면
EC2 인스턴스를 종료하여 삭제처리 해주어야 추가 비용이 청구되지 않는다.
EIP는 EC2와 연결되어 있을 때만 과금이 된다.
Route 53dms 존 단위로 월정액이 과금되니 사용하지 않는다면 삭제할 필요가 있다.
VPC는 유지 자체는 비용이 들지 않으니 제거할 필요 없다.
'공부 > AWS 및 서버 관련' 카테고리의 다른 글
| [GitHub Actions] Spring 프로젝트 CI 구축하기 (1) | 2025.04.15 |
|---|---|
| AWS 패턴 2: 기업 웹사이트 (1) | 2025.04.13 |
| 네트워크 가상화(Network Virtualization) 간단 요약 (2) | 2025.03.24 |

Ahan
책, 영화, 게임! 인생의 활력 요소가 되는 취미들을 하자!
